Por que esperamos que o valor de $\chi^2$ seja próximo ao NGL ($\nu$)?
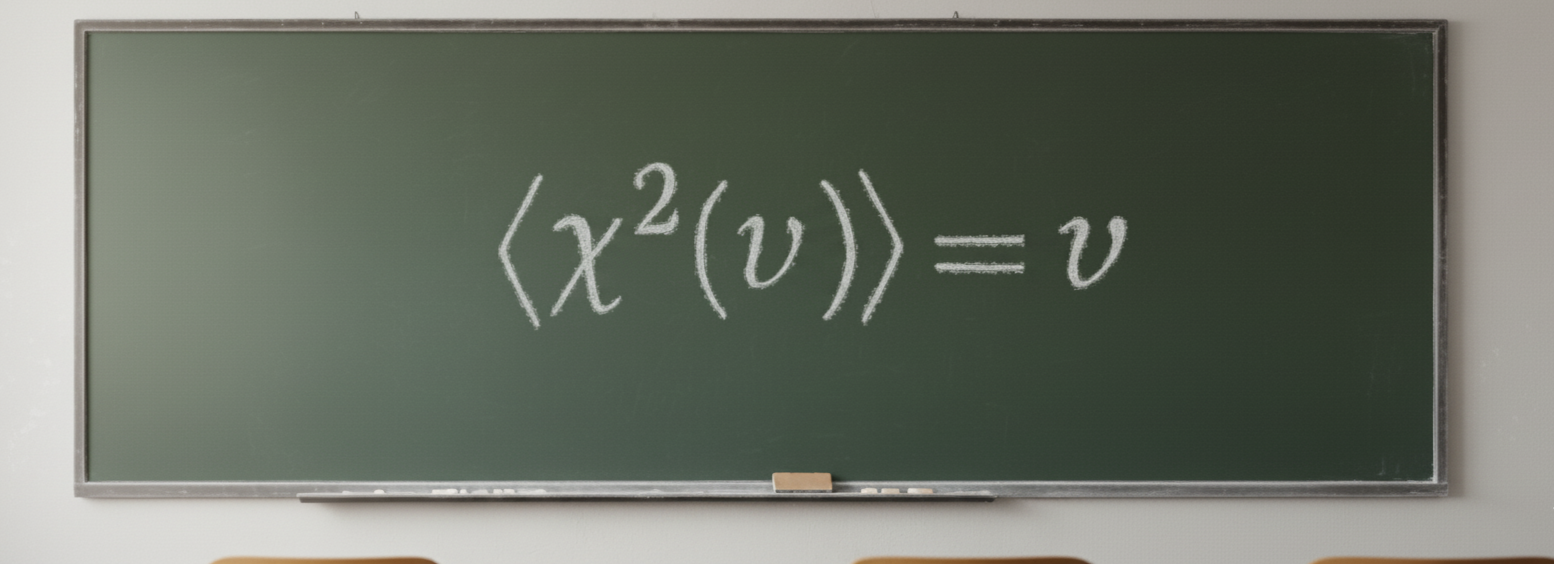
Dedução
Antes da conta: o que significa valor esperado?
Antes de deduzir por que o valor esperado de uma variável qui-quadrado é igual ao número de graus de liberdade, vale fixar uma ideia mais básica: o que é valor esperado?
O valor esperado de uma variável aleatória é a média que esperamos obter quando um mesmo experimento é repetido muitas vezes nas mesmas condições. Ele não precisa ser o valor observado em uma tentativa específica, nem o valor mais provável. Ele representa a média estatística de longo prazo.
Um exemplo mais intuitivo do que “idades em uma sala” é o tempo de espera na fila do bandejão. Suponha que, ao chegar em um certo horário, o tempo de espera $T$ seja:
- 2 min com probabilidade 0,2
- 5 min com probabilidade 0,5
- 12 min com probabilidade 0,3
Nesse caso, o valor esperado é
$$\langle T \rangle = 2(0{,}2) + 5(0{,}5) + 12(0{,}3) = 6{,}5 \text{ min}$$
Isso não quer dizer que, em um dia específico, você necessariamente esperará 6,5 minutos. Quer dizer que, se essa situação fosse repetida muitas vezes, a média dos tempos observados tenderia a 6,5 minutos.
De forma geral, para uma variável discreta $X$,
$$\langle X \rangle = \sum_x x\,P(X=x)$$
Essa é a ideia central que vamos usar no caso da distribuição qui-quadrado.
1. Como a estatística $\chi^2$ aparece em física experimental
Em física experimental, a estatística qui-quadrado aparece naturalmente quando queremos medir o desvio entre os dados observados e os valores previstos por um modelo. Uma forma comum de escrevê-la é
$$\chi^2 = \sum_{i=1}^{N} \frac{(y_i - f_i)^2}{\sigma_i^2}$$
onde:
- $y_i$ é o valor medido no ponto $i$;
- $f_i$ é o valor previsto pelo modelo;
- $\sigma_i$ é a incerteza associada a esse ponto.
Cada termo da soma mede o tamanho do desvio entre dado e modelo em unidades da própria incerteza. Se definirmos o resíduo normalizado
$$r_i = \frac{y_i - f_i}{\sigma_i},$$
então a estatística fica
$$\chi^2 = \sum_{i=1}^{N} r_i^2.$$
Se o modelo estiver correto e os erros forem gaussianos, independentes e bem estimados, então cada resíduo normalizado se comporta como uma variável normal padrão. Em outras palavras, podemos pensar que
$$Z_i \sim N(0,1)$$
e, em alto nível, a variável qui-quadrado pode ser construída como
$$X = \sum_{i=1}^{\nu} Z_i^2,$$
com $Z_1$, $Z_2$, $\ldots$, $Z_\nu$ independentes.
Aqui, $\nu$ é o número de graus de liberdade. Em muitos ajustes experimentais,
$$\nu = N - p,$$
onde $N$ é o número de dados e $p$ é o número de parâmetros ajustados.
2. O objetivo da dedução
Agora queremos calcular o valor esperado de $X$, isto é,
$$\langle X \rangle.$$
Usando a linearidade do valor esperado, temos
$$\langle X \rangle = \left\langle \sum_{i=1}^{\nu} Z_i^2 \right\rangle = \sum_{i=1}^{\nu} \langle Z_i^2 \rangle.$$
Portanto, toda a dedução se reduz a descobrir quanto vale $\langle Z_i^2 \rangle$.
3. Relação com a variância
Para qualquer variável aleatória $Y$, a variância é definida por
$$ \langle (Y-\langle x\rangle)^2 \rangle\equiv \mathrm{Var}(Y) = \langle Y^2 \rangle - \langle Y \rangle^2.$$
Reorganizando a expressão, obtemos
$$\langle Y^2 \rangle = \mathrm{Var}(Y) + \langle Y \rangle^2.$$
Essa identidade será aplicada às variáveis $Z_i$.
4. Propriedades da normal padrão
Como cada $Z_i$ segue uma distribuição normal padrão,
$$Z_i \sim N(0,1),$$
sabemos que
$$\langle Z_i \rangle = 0$$
e
$$\mathrm{Var}(Z_i) = 1.$$
Substituindo esses valores na relação anterior, obtemos
$$\langle Z_i^2 \rangle = \mathrm{Var}(Z_i) + \langle Z_i \rangle^2 = 1 + 0^2 = 1.$$
Esse resultado é o ponto-chave da dedução: o quadrado de uma variável normal padrão contribui, em média, com 1.
5. Conclusão da dedução
Voltando à expressão para $\langle X \rangle$,
$$\langle X \rangle = \sum_{i=1}^{\nu} \langle Z_i^2 \rangle,$$
e usando o fato de que $\langle Z_i^2 \rangle = 1$, segue que
$$\langle X \rangle = \sum_{i=1}^{\nu} 1 = \underbrace{1 + 1 + \cdots + 1}_{\nu \text{ vezes}} = \nu.$$
Como $X$ é justamente uma variável com distribuição qui-quadrado com $\nu$ graus de liberdade, concluímos que
$$\boxed{\langle \chi^2 \rangle = \nu.}$$
6. Interpretação física do resultado
Esse resultado tem uma interpretação importante. Cada termo da soma representa a contribuição quadrática de um desvio normalizado. Como cada um desses termos vale, em média, 1, então a soma de $\nu$ deles vale, em média, $\nu$.
Por isso, quando um ajuste está consistente com os dados e com as incertezas experimentais, esperamos que o valor de $\chi^2$ esteja na ordem do número de graus de liberdade.
Isso também explica por que é tão comum analisar o qui-quadrado reduzido,
$$\chi^2_{\mathrm{red}} = \frac{\chi^2}{\nu}.$$
Se tudo estiver consistente, espera-se que
$$\langle \chi^2_{\mathrm{red}} \rangle = 1.$$
7. Um detalhe importante: “próximo de $\nu$” não significa “igual a $\nu$”
É importante não interpretar esse resultado de forma rígida demais. A relação
$$\langle \chi^2 \rangle = \nu$$
fala sobre o valor esperado, isto é, sobre a média de muitas repetições. Em um experimento específico, o valor observado de $\chi^2$ pode ser maior ou menor que $\nu$.
Em outras palavras, não esperamos que todo ajuste produza exatamente $\chi^2 = \nu$. O que esperamos é que, em média, a estatística esteja nessa escala. É justamente isso que a simulação numérica abaixo vai ajudar a visualizar.
Simulação para demonstração
A dedução analítica mostrou que, para uma variável aleatória com distribuição qui-quadrado com $\nu$ graus de liberdade, o valor esperado é
$$\langle \chi^2 \rangle = \nu.$$
Mas essa afirmação fala sobre uma média estatística de muitas repetições, e não sobre o resultado de uma única realização. É justamente por isso que uma simulação numérica é tão útil: ela permite enxergar, de forma concreta, o que significa valor esperado.
A ideia do código é reproduzir numericamente a própria construção da variável qui-quadrado. Em cada experimento simulado, geramos $\nu$ variáveis aleatórias independentes com distribuição normal padrão, elevamos cada uma ao quadrado e somamos os resultados. Em símbolos,
$$\chi^2 = \sum_{i=1}^{\nu} Z_i^2,$$
com $Z_1$, $Z_2$, $\ldots$, $Z_\nu$ independentes e distribuídas como $N(0,1)$.
Ao repetir esse procedimento muitas vezes, obtemos uma coleção de valores de $\chi^2$. A partir dela, podemos observar três aspectos complementares:
- como um único valor de $\chi^2$ é construído;
- como a distribuição de $\chi^2$ aparece quando acumulamos muitas amostras;
- como a média acumulada dos valores simulados converge para $\nu$.
Essa terceira observação é a mais importante do ponto de vista conceitual, porque ela traduz visualmente o significado de valor esperado.
0. Estrutura geral da simulação
O código foi organizado para responder a três perguntas didáticas:
1. Como nasce uma única amostra de $\chi^2$?
2. Como fica a distribuição de $\chi^2$ após muitas repetições?
3. Como a média das simulações se aproxima do valor teórico $\nu$?
Em vez de tratar a distribuição qui-quadrado como uma expressão abstrata, a simulação a constrói diretamente a partir de suas variáveis de origem. Isso torna visível a relação entre a definição matemática e o comportamento estatístico observado.
============================================================ SIMULAÇÃO DIDÁTICA DA DISTRIBUIÇÃO QUI-QUADRADO ============================================================ Graus de liberdade (nu) = 20 Número de simulações = 50000 Valor esperado teórico = <chi^2> = nu = 20 Variância teórica = Var(chi^2) = 2*nu = 40 ============================================================
1. Construção de uma única realização de $\chi^2$
O primeiro gráfico mostra uma única realização da soma
$$\chi^2 = Z_1^2 + Z_2^2 + \cdots + Z_\nu^2.$$
Nele, cada barra representa a contribuição individual de um termo $Z_i^2$. Além disso, o gráfico exibe uma linha horizontal em $1$, que corresponde ao valor esperado de cada uma dessas contribuições:
$$\langle Z_i^2 \rangle = 1.$$
Esse gráfico é importante porque ele mostra que os termos individuais flutuam bastante. Alguns podem ficar abaixo de $1$, outros acima, e alguns podem até ser bem grandes. Ou seja: em uma realização específica, não há motivo para esperar que cada termo seja exatamente igual a $1$.
O ponto central é outro: quando olhamos para muitos termos independentes, a soma deles tende a produzir um valor total cuja média, ao longo de muitas repetições, será $\nu$.
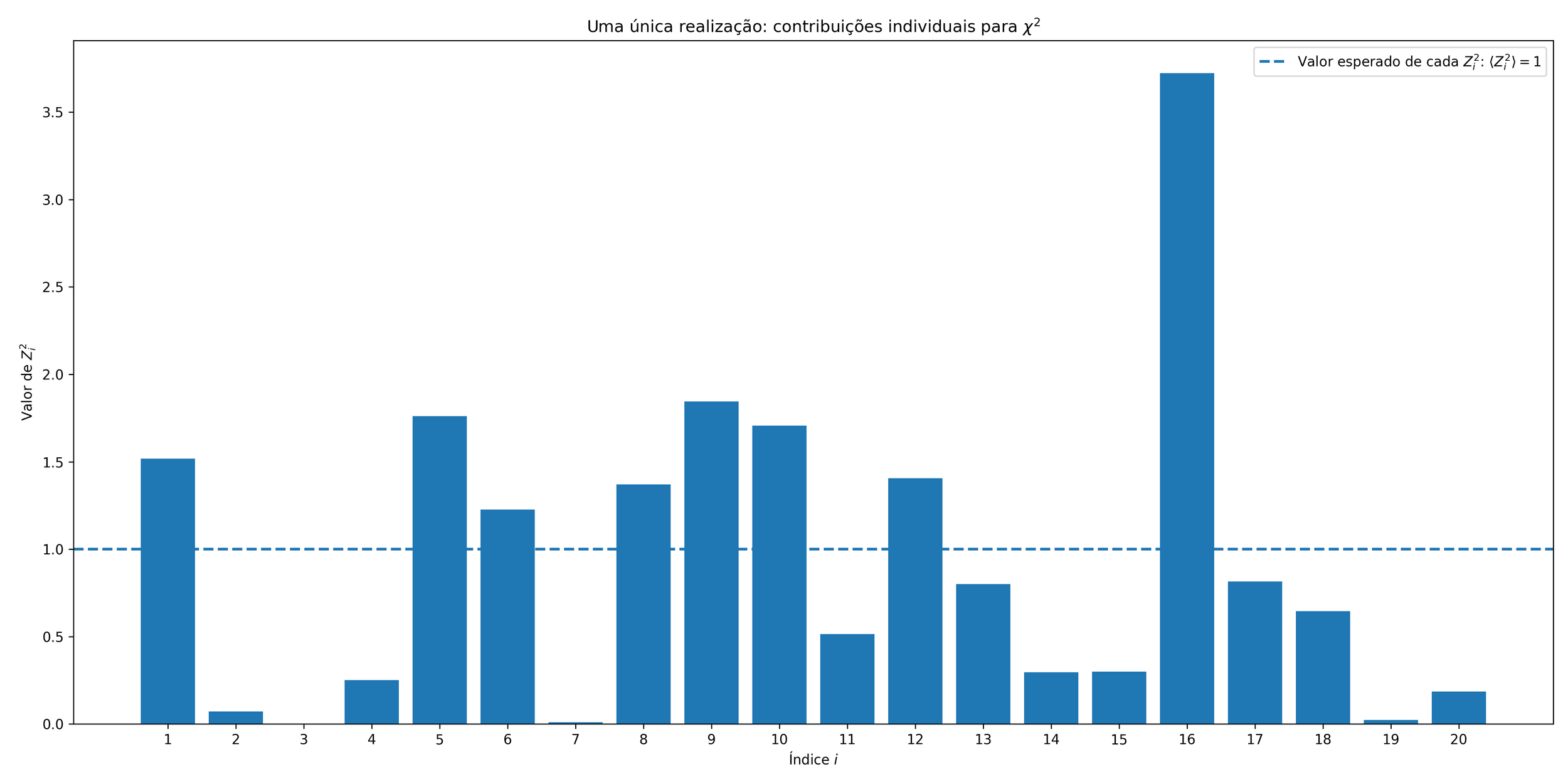
Gráfico 1: contribuições individuais para uma única realização de $\chi^2$
[ETAPA 1] Construção de UMA única amostra de chi^2 ------------------------------------------------------------ i Z_i Z_i^2 ------------------------------------------------------------ 1 -1.231665 1.516999 2 0.267119 0.071353 3 -0.006926 0.000048 4 0.501535 0.251538 5 -1.326728 1.760208 6 1.107768 1.227150 7 0.093755 0.008790 8 -1.170818 1.370815 9 -1.358240 1.844817 10 -1.306564 1.707110 11 -0.717615 0.514972 12 1.185621 1.405698 13 0.894534 0.800191 14 -0.544048 0.295988 15 -0.546588 0.298758 16 1.929588 3.723309 17 0.902789 0.815027 18 -0.803391 0.645436 19 -0.149712 0.022414 20 -0.430292 0.185151 ------------------------------------------------------------ Somatório dos Z_i^2 = chi^2 = 18.465770
2. Histograma da distribuição simulada de $\chi^2$
O segundo gráfico mostra o histograma dos muitos valores de $\chi^2$ gerados pela simulação. Cada experimento fornece um único número, e o histograma mostra como esses números se distribuem.
Esse gráfico ajuda a perceber duas coisas importantes.
Primeiro, a distribuição não é simétrica como uma gaussiana. Para valores relativamente pequenos de $\nu$, ela costuma apresentar assimetria e uma cauda à direita. Isso já mostra que o valor esperado não deve ser confundido com “o centro geométrico” no sentido visual mais ingênuo.
Segundo, o gráfico marca com linhas verticais tanto o valor teórico esperado quanto a média obtida numericamente. Em uma simulação bem feita, essas duas linhas devem ficar muito próximas. Isso mostra que os dados simulados reproduzem a propriedade
$$\langle \chi^2 \rangle = \nu.$$
Esse gráfico é útil para enxergar a forma global da distribuição, mas sozinho ainda não comunica completamente o significado de valor esperado. Para isso, o gráfico mais instrutivo é o próximo.
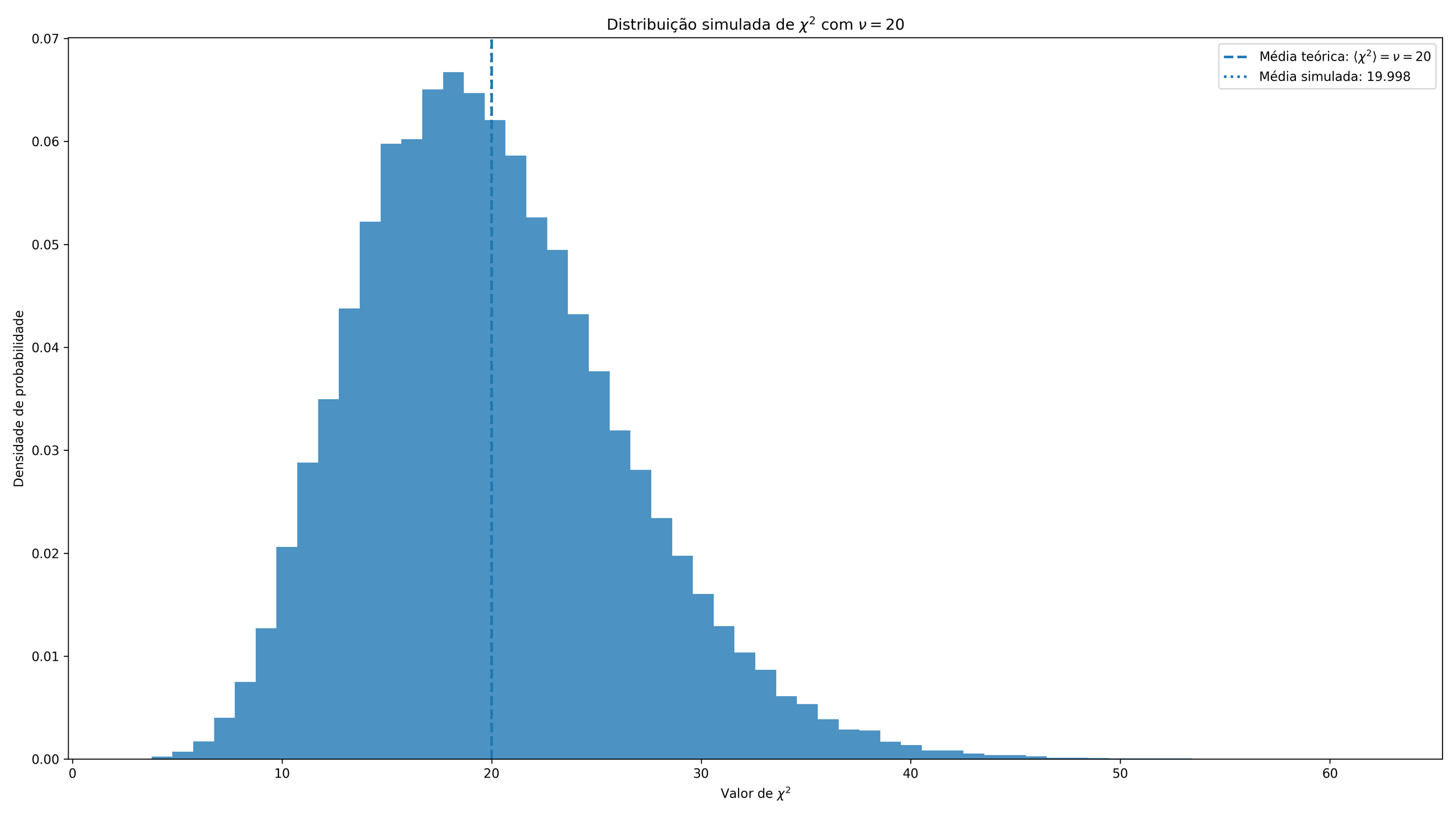
Gráfico 2: histograma da distribuição simulada de $\chi^2$
[ETAPA 2] Estatísticas obtidas após muitas simulações ------------------------------------------------------------ Média teórica = 20.000000 Média simulada = 19.998291 Variância teórica = 40.000000 Variância simulada = 39.756755 ------------------------------------------------------------
3. Média acumulada e o significado de valor esperado
O terceiro gráfico é o mais didático de todos. Ele mostra a média acumulada dos valores simulados de $\chi^2$ à medida que o número de experimentos aumenta.
Se chamarmos de $\chi_1^2, \chi_2^2, \ldots, \chi_N^2$ os valores obtidos nas simulações, então a média acumulada após $N$ experimentos é
$$\overline{\chi^2}_N = \frac{1}{N}\sum_{k=1}^{N} \chi_k^2.$$
À medida que $N$ cresce, essa média acumulada oscila cada vez menos e se aproxima de $\nu$. É exatamente isso que devemos entender por valor esperado: não o resultado de uma única realização, mas o valor para o qual a média de muitas realizações tende.
Esse gráfico materializa, de forma visual, a afirmação teórica
$$\langle \chi^2 \rangle = \nu.$$
Em outras palavras, ele mostra numericamente a ideia central de que o valor esperado é uma propriedade de longo prazo.
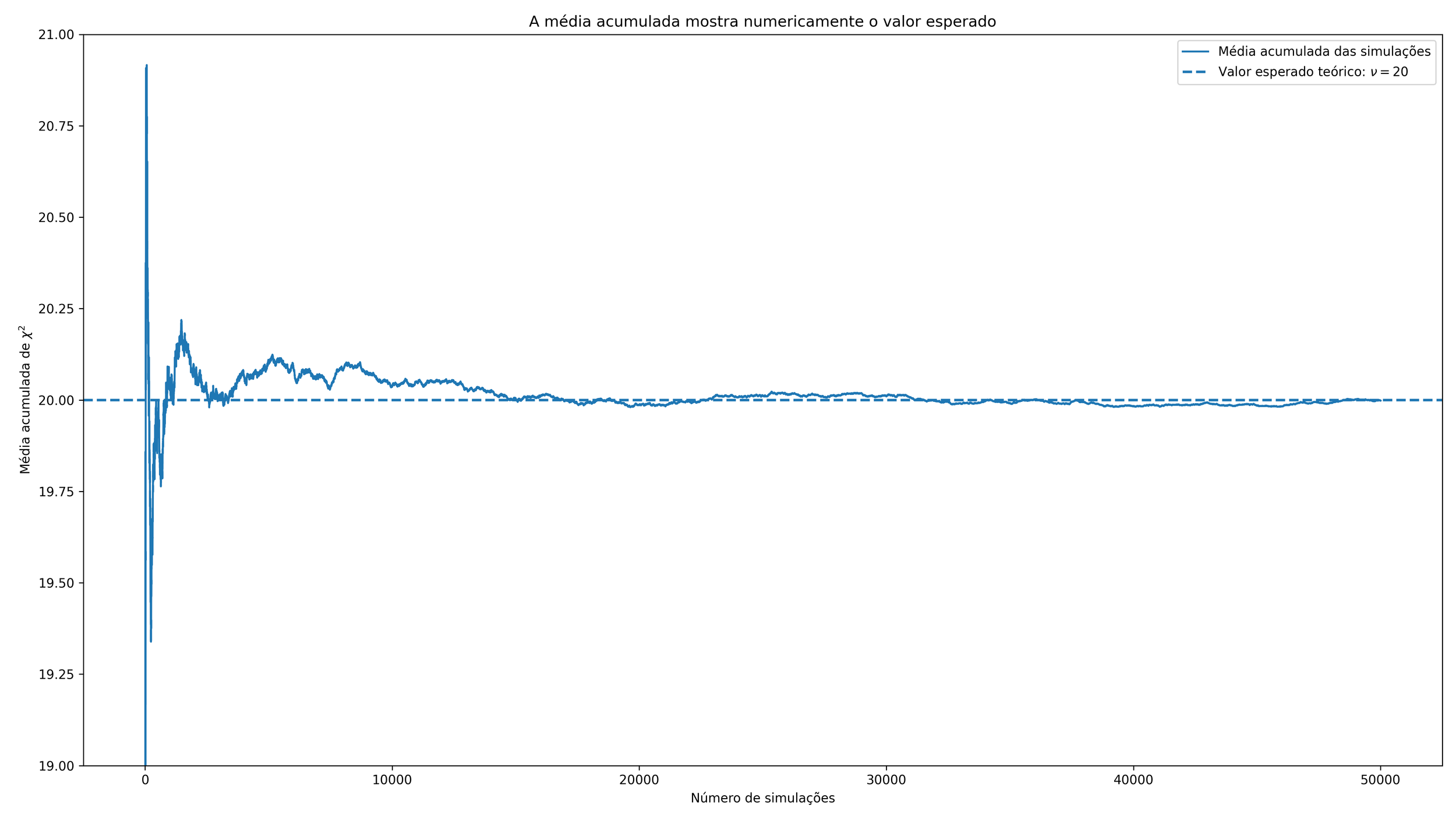
Gráfico 3: convergência da média acumulada para $\nu$
[ETAPA 3] Conclusão numérica ------------------------------------------------------------ Erro relativo da média = 0.0085% Erro relativo da variância = 0.6081% ------------------------------------------------------------ Interpretação: À medida que o número de simulações cresce, a média dos valores simulados de chi^2 tende a nu. Isso é a manifestação numérica da ideia de valor esperado.
4. O que esta simulação ensina, afinal?
O papel desta simulação não é “provar” a matemática, porque a prova já foi feita analiticamente. O papel dela é complementar a dedução com uma visualização concreta.
Ela mostra que:
- uma única realização de $\chi^2$ pode flutuar bastante;
- a distribuição de $\chi^2$ tem uma forma característica, que depende de $\nu$;
- quando repetimos o processo muitas vezes, a média dos valores simulados tende ao valor esperado teórico.
Isso ajuda a corrigir uma confusão comum: o fato de $\langle \chi^2 \rangle = \nu$ não significa que todo experimento produzirá exatamente $\chi^2 = \nu$. Significa que, em média, os valores obtidos tenderão a essa escala.
5. Relação com a prática experimental
Na prática da física experimental, essa interpretação é essencial. Quando ajustamos um modelo a um conjunto de dados, o valor de $\chi^2$ obtido em um caso particular pode ficar acima ou abaixo de $\nu$. Isso é normal. O que importa é saber se ele está em uma faixa compatível com as flutuações esperadas para a distribuição.
Por isso, a simulação também prepara o terreno para interpretar melhor o qui-quadrado reduzido,
$$\chi^2_{\mathrm{red}} = \frac{\chi^2}{\nu},$$
cujo valor esperado é
$$\langle \chi^2_{\mathrm{red}} \rangle = 1.$$
A leitura física é direta: se os resíduos são compatíveis com o modelo e com as incertezas, espera-se que o qui-quadrado reduzido fique da ordem de $1$.
6. Como ler o código que vem a seguir
Com essa interpretação em mente, o código abaixo pode ser lido em três blocos:
- primeiro, ele constrói uma única amostra de $\chi^2$ para mostrar a soma dos termos $Z_i^2$;
- depois, ele gera muitas amostras para formar a distribuição simulada;
- por fim, ele calcula a média acumulada para mostrar numericamente a ideia de valor esperado.
Assim, o código deixa de ser apenas uma implementação computacional e passa a funcionar como uma ponte entre definição matemática, interpretação estatística e intuição física.
Código
# ============================================================
# SIMULAÇÃO DIDÁTICA DA DISTRIBUIÇÃO QUI-QUADRADO
# ============================================================
# Objetivo:
# 1) Mostrar como um único valor de chi^2 é construído
# 2) Simular muitos valores de chi^2
# 3) Verificar numericamente que <chi^2> = nu
# 4) Mostrar a média acumulada convergindo para nu
#
# Requisitos:
# pip install numpy matplotlib
# ============================================================
import numpy as np
import matplotlib.pyplot as plt
# Configuração global de alta resolução
plt.rcParams['figure.dpi'] = 100
plt.rcParams['savefig.dpi'] = 300 # Resolução ainda maior ao salvar arquivos
# ============================================================
# 1. PARÂMETROS DA SIMULAÇÃO
# ============================================================
nu = 20 # número de graus de liberdade
n_simulacoes = 50000 # número de experimentos simulados
fator_convergencia=0.05 # % de convergência
convergencia_limite=(1-fator_convergencia)*nu,(1+fator_convergencia)*nu # limite de convergência
# A seed era 42 (resposta sobre a vida, o universo e tudo mais),
# mas mudei para 41 para ficar mais "bonitinho", rs
seed = 41 # semente para reprodutibilidade
salvar_imagens = True # Toggle: True para salvar .png, False para apenas mostrar
rng = np.random.default_rng(seed)
# rng = np.random.default_rng()
print("=" * 60)
print("SIMULAÇÃO DIDÁTICA DA DISTRIBUIÇÃO QUI-QUADRADO")
print("=" * 60)
print(f"Graus de liberdade (nu) = {nu}")
print(f"Número de simulações = {n_simulacoes}")
print(f"Valor esperado teórico = <chi^2> = nu = {nu}")
print(f"Variância teórica = Var(chi^2) = 2*nu = {2 * nu}")
print("=" * 60)
# ============================================================
# 2. UMA ÚNICA AMOSTRA: COMO NASCE UM VALOR DE chi^2
# ============================================================
# Geramos nu variáveis normais padrão independentes Z_i ~ N(0,1)
z_exemplo = rng.normal(loc=0.0, scale=1.0, size=nu)
# Elevamos cada uma ao quadrado
z2_exemplo = z_exemplo**2
# Somamos tudo: esse é um único valor da variável chi^2
chi2_exemplo = np.sum(z2_exemplo)
print("\n[ETAPA 1] Construção de UMA única amostra de chi^2")
print("-" * 60)
print("i Z_i Z_i^2")
print("-" * 60)
for i, (z, z2) in enumerate(zip(z_exemplo, z2_exemplo), start=1):
print(f"{i:2d} {z:12.6f} {z2:12.6f}")
print("-" * 60)
print(f"Somatório dos Z_i^2 = chi^2 = {chi2_exemplo:.6f}")
# ============================================================
# 3. MUITAS SIMULAÇÕES: GERANDO A DISTRIBUIÇÃO chi^2
# ============================================================
# Em vez de fazer um loop com append, geramos tudo de uma vez.
# Cada linha da matriz representa um experimento completo.
z_todos = rng.normal(loc=0.0, scale=1.0, size=(n_simulacoes, nu))
# Cada valor de chi^2 é a soma dos quadrados em uma linha
chi2_valores = np.sum(z_todos**2, axis=1)
# Estatísticas simuladas
media_simulada = np.mean(chi2_valores)
var_simulada = np.var(chi2_valores)
# Estatísticas teóricas
media_teorica = nu
var_teorica = 2 * nu
print("\n[ETAPA 2] Estatísticas obtidas após muitas simulações")
print("-" * 60)
print(f"Média teórica = {media_teorica:.6f}")
print(f"Média simulada = {media_simulada:.6f}")
print()
print(f"Variância teórica = {var_teorica:.6f}")
print(f"Variância simulada = {var_simulada:.6f}")
print("-" * 60)
# ============================================================
# 4. MÉDIA ACUMULADA: A IDEIA DE VALOR ESPERADO EM AÇÃO
# ============================================================
# A média acumulada mostra como a média das simulações vai
# se aproximando do valor esperado teórico à medida que o
# número de experimentos aumenta.
media_acumulada = np.cumsum(chi2_valores) / np.arange(1, n_simulacoes + 1)
# ============================================================
# 5. GRÁFICO 1 — CONTRIBUIÇÕES Z_i^2 DE UMA ÚNICA AMOSTRA
# ============================================================
# Proporção 10x5 (2:1) para melhor visualização horizontal das barras
plt.figure(figsize=(16, 8))
plt.bar(np.arange(1, nu + 1), z2_exemplo)
plt.axhline(1, linestyle='--', linewidth=2, label=r'Valor esperado de cada $Z_i^2$: $\langle Z_i^2 \rangle = 1$')
plt.title(r'Uma única realização: contribuições individuais para $\chi^2$')
plt.xlabel(r'Índice $i$')
plt.ylabel(r'Valor de $Z_i^2$')
plt.xticks(np.arange(1, nu + 1))
plt.legend()
plt.tight_layout()
if salvar_imagens:
plt.savefig('fig1_contribuicoes.png')
plt.show()
# ============================================================
# 6. GRÁFICO 2 — HISTOGRAMA DA DISTRIBUIÇÃO chi^2
# ============================================================
plt.figure(figsize=(16, 9))
plt.hist(chi2_valores, bins=60, density=True, alpha=0.8)
plt.axvline(media_teorica, linestyle='--', linewidth=2,
label=rf'Média teórica: $\langle \chi^2 \rangle = \nu = {media_teorica}$')
plt.axvline(media_simulada, linestyle=':', linewidth=2,
label=rf'Média simulada: {media_simulada:.3f}')
plt.title(rf'Distribuição simulada de $\chi^2$ com $\nu={nu}$')
plt.xlabel(r'Valor de $\chi^2$')
plt.ylabel('Densidade de probabilidade')
plt.legend()
plt.tight_layout()
if salvar_imagens:
plt.savefig('fig2_histograma.png')
plt.show()
# ============================================================
# 7. GRÁFICO 3 — CONVERGÊNCIA DA MÉDIA ACUMULADA
# ============================================================
plt.figure(figsize=(16, 9))
plt.plot(media_acumulada, linewidth=1.5,
label=r'Média acumulada das simulações')
plt.axhline(media_teorica, linestyle='--', linewidth=2,
label=rf'Valor esperado teórico: $\nu={media_teorica}$')
plt.ylim(convergencia_limite[0], convergencia_limite[1])
plt.title(r'A média acumulada mostra numericamente o valor esperado')
plt.xlabel('Número de simulações')
plt.ylabel(r'Média acumulada de $\chi^2$')
plt.legend()
plt.tight_layout()
if salvar_imagens:
plt.savefig('fig3_convergencia.png')
plt.show()
# ============================================================
# 8. CONCLUSÃO NUMÉRICA
# ============================================================
erro_relativo_media = abs(media_simulada - media_teorica) / media_teorica
erro_relativo_var = abs(var_simulada - var_teorica) / var_teorica
print("\n[ETAPA 3] Conclusão numérica")
print("-" * 60)
print(f"Erro relativo da média = {100 * erro_relativo_media:.4f}%")
print(f"Erro relativo da variância = {100 * erro_relativo_var:.4f}%")
print("-" * 60)
print("Interpretação:")
print("À medida que o número de simulações cresce,")
print("a média dos valores simulados de chi^2 tende a nu.")
print("Isso é a manifestação numérica da ideia de valor esperado.")